일론 머스크가 투자하고 마이크로소프트가 지원하는 오픈AI가 일으킨 챗GPT 돌풍이 점점 거세지고 있다. 오픈 AI는 지난 3월 15일 GPT-4를 공개하며 기능과 능력을 한층 고도화했다. 포브스코리아는 챗GPT의 핵심기술인 대규모 언어 모델(LLM, Large Language Model) 개념을 간단히 살펴보고 관련 특허를 분석했다. 특허를 보유한 핵심 기업들의 동향과 함께 오픈AI의 지식재산권(IP) 전략을 살펴봤다.
우선 오픈AI의 챗GPT 능력을 쉽게 수치로 가늠해보자. 오픈AI의 챗GPT(GPT-3.5 버전)는 지난해 11월 공개 이후 두 달 만에 1억 명 넘는 사용자를 확보했고, 현재 2주 만에 인류의 모든 인쇄 작업에 해당하는 양을 능가하는 텍스트를 생성하는 것으로 추정된다.인공지능 분야의 세계적 석학 앨런 톰슨 박사가 전미경제연구소(National Bureau of Economic Research)의 보고서를 인용해 추정한 결과, 챗GPT는 지난 3월 기준으로 분당 3억1000만 단어(WPM) 이상 생성한다. 그리고 구글북스에서 실시한 연구에 따르면 1440년 구텐베르크의 인쇄기가 발명된 이래 출판된 책은 1억2984만4880권이고 1권당 평균 5만 단어라고 볼 때 인류는 총 6조5000억 단어의 지식을 생산했다. 이 수치를 단순 비교해보면, 챗GPT의 문서 생산량은 단 14일이면 인류의 모든 출판물의 단어 생산량을 뛰어넘는다.다른 비교를 하나 더 해보자면, 소셜미디어 트위터는 분당 35만 개 트윗을 출력하며 평균 8단어(34자)로 볼 때 전체 문서 생산량은 분당 280만 단어다. 따라서 챗GPT는 인간 트위터 사용자가 써내는 양의 110배 이상을 매일 출력하고 있는 셈이다.
챗GPT의 언어 생성은 대규모 언어 모델(LLM) 기술을 기반으로 한다. 언어 모델링을 쉽게 설명하면, 텍스트 문자열에 대한 확률 분포를 연구하는 것이다. 자연어 처리(NLP)에서 가장 기본적인 작업 중 하나다. 현재 이 기술은 텍스트 생성, 음성 인식, 기계 번역 등에 널리 사용되고 있다. 기존의 언어 모델(CLM)은 인과적 방식으로 언어 시퀀스의 확률을 예측하는 것을 목표로 하는 반면, 사전 훈련된 언어 모델(PLM)은 더 넓은 개념을 다루며 다운스트림 애플리케이션을 위한 인과적 순차 모델링 과 미세조정 모두에 사용할 수 있다는 차이가 있다.
조금만 더 기술적으로 깊이 들어가보자. 챗GPT의 대화 시스템은 생성 언어 모델의 미세조정 버전이다. 챗GPT는 1880억 개 이상의 매개변수가 있는 생성 언어 모델에 의해 구현된다. 그리고 레이블이 지정된 데이터에 대한 지도학습 및 강화학습을 통해 추가로 미세조정된다.언어 모델은 대화가 가능하도록 자연어 이해(NLU)와 자연어 생성(NLG)에 의해 구현된다. NLU는 사용자의 의도를 이해하고 인식하는 역할을 한 후, 훈련언어모델 인코더가 그 내용에 대해 유익한 표현을 제공하고 적절하게 응답을 생성하는 프로세스다.
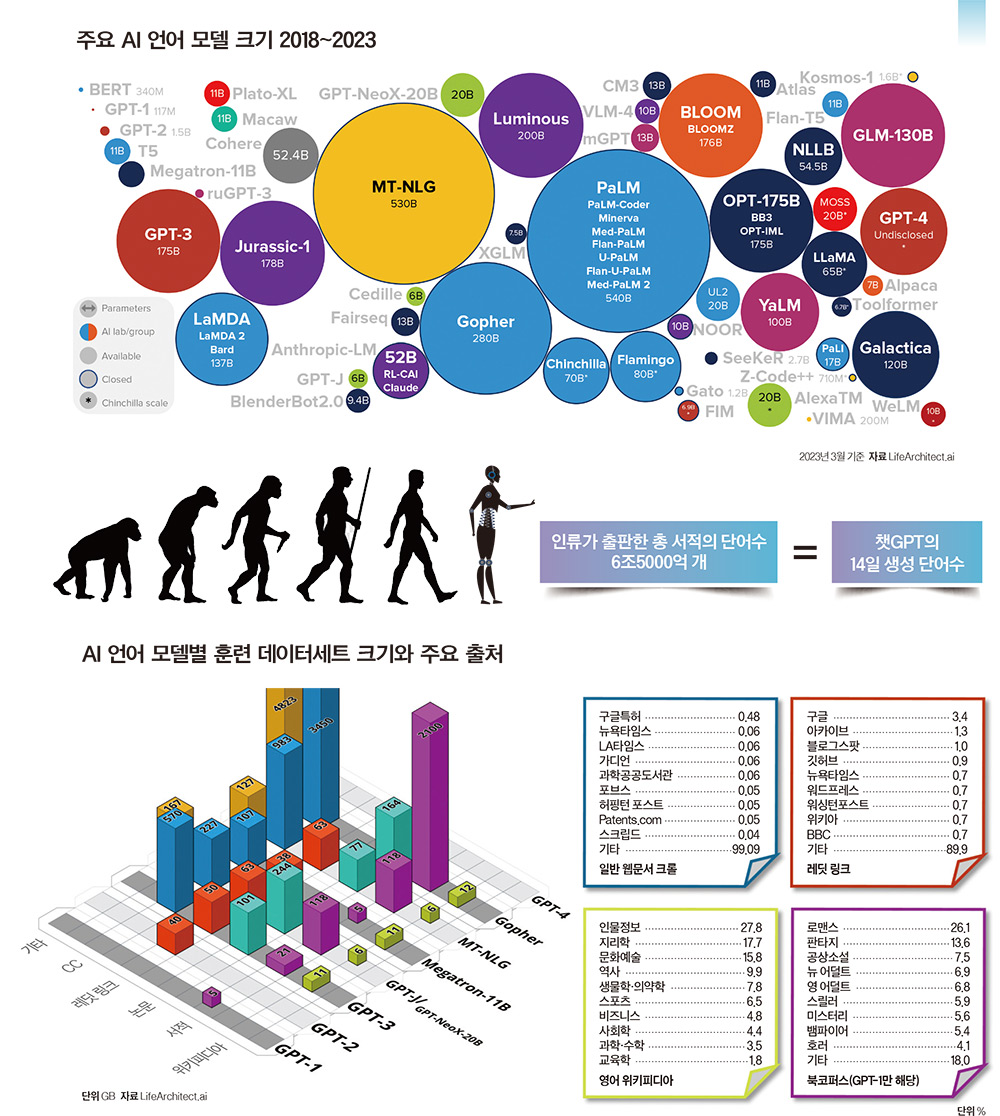
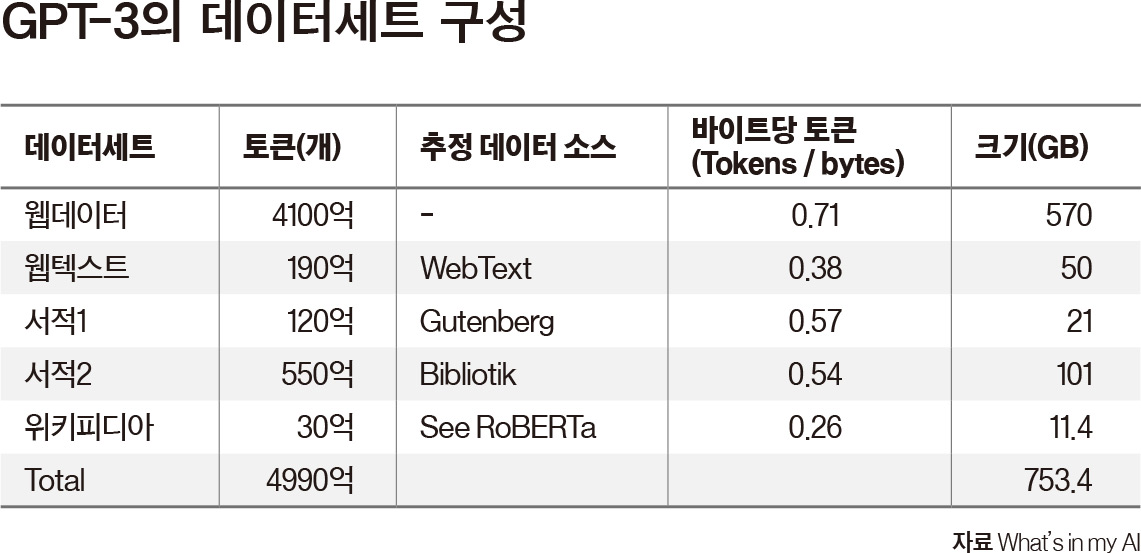
챗GPT의 훈련 데이터와 진화GPT-3.5는 GPT-3의 학습 데이터를 기반으로 하며 쓰기, 복잡한 명령, 더 긴 문장 생성 등 기능을 업그레이드한 버전이다. 따라서 기존 학습 데이터에 훈련 데이터를 추가한 2022년 1월 27일까지의 학습을 기반으로 출력물을 만든다. 그래서 챗GPT는 이때까지 훈련된 내용만 답할 수 있었고 지난 1년여간 새로 발생한 지식들을 포함하지 못하는 한계가 있었다.챗GPT는 트랜스포머라는 딥러닝 모델 아키텍처를 이용하는데, 실제 이 기술이 2017년 개발된 후 초거대 AI가 비약적으로 발전했다. 하지만 트랜스포머 기반으로 하는 대부분의 LLM은 웹에 액세스할 수 없다. 별도의 신경망 층이 있어야 실시간 웹 접속이 가능한데, 최근 마이크로소프트의 ‘빙챗’과 구글의 ‘바드’가 웹 액세스 층을 갖춰 실시간 웹 정보를 가져올 수 있다는 장점을 내세우고 있다.따라서 2022년 1월에 머물러 있는 GPT-3의 훈련에 사용된 데이터는 세부 사항이 공개되지 않았지만 언론, 논문, 특허, 레딧, 위키피디아 등의 텍스트 데이터로 알려져 있다. 결론적으로 훈련 텍스트 데이터는 수조 개 단어 간에 수십억 개의 연결을 만들었고 그 최종 크기는 매개변수 1750억 개, 토큰(단어 조각) 3000억 개에 이른다.훈련 데이터의 주요 출처를 더 자세히 살펴보면, 영어 위키피디아는 인물전기(27.8%), 지리학(17.7%), 문화예술(15.8%), 역사(9.9%), 생물학·의약학(7.8%), 스포츠(6.5%), 비즈니스(4.8%), 기타 사회학(4.4%), 과학·수학(3.5%), 교육학(1.8%)으로 구성됐다. 그리고 웹문서는 구글특허(0.48%), 뉴욕타임스(0.06%) LA타임스(0.06%), 더가디언(0.06%), 공공과학도서관(0.06%), 포브스(0.05%), 허핑턴포스트(0.05%) 등이다.한편, 블룸버그, 뉴스코프(월스트리트저널), CNN 등 뉴스매체는 언론인의 생산물을 무단으로 인공지능 도구를 학습시키기 위해 사용한 것에 대해 저작권 침해 여부를 검토하고 있거나 소송을 제기했다. 오픈AI가 모든 매체와 저작권 계약을 체결했는지는 아직 불확실하며 허가 없이 데이터를 스크랩한 경우는 발행인의 서비스 약관에 위배된다.다시 챗GPT의 대규모 언어 모델 기술 이야기로 돌아가면, 오픈AI는 지난 3월 15일 세간의 귀추가 주목된 GPT-4를 공개했다. 공개 첫날, 소송 초안 작성, 표준화 시험 통과, 손으로 그린 스케치로 웹사이트 구축 기능 등을 선보여 많은 사용자를 놀라게 했다.
기존 모델과 비교해 가장 큰 변화는 LLM에 시각적 언어 모델(Visual Language Model)을 포함했다는 것이다. 즉, 질문 입력을 넘어 사용자가 이미지를 업로드하면 그에 따라 작업이 가능하다는 점이다. GPT-4의 비디오데모에서 시연자가 이미지를 GPT-4에서 업로드하니 결과 코드가 텍스트로 출력됐다. 그 코드를 그대로 붙여넣으면 제대로 작동하는 웹사이트가 만들어졌다. 개발자들의 전유물이었던 코딩이 제로 시대로 접어들었음을 시사했다. GPT-4가 공개된 이후 코딩 지식이 전혀 없는 사용자들은 GPT-4가 제공하는 지침에 따라 작업한 결과, 테트리스, 스네이크와 같은 초기 단계 게임을 재현했고 어떤 이들은 자신만의 독창적인 게임을 제작했다.
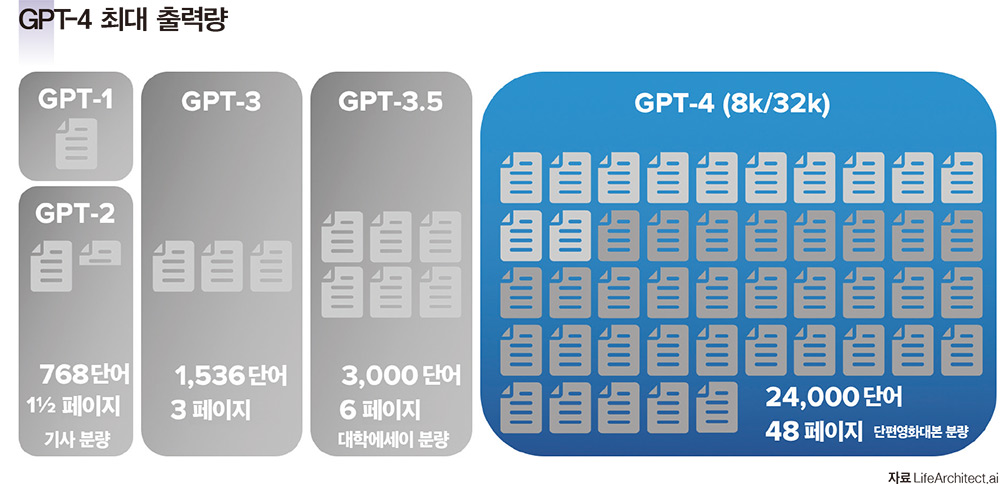
GPT-4의 매개변수는 공개되지 않았으나 톰슨 박사의 추정에 따르면 텍스트 800억~1400억 개, 이미지 200억 개다. 토큰 수 역시 공개되지 않았지만 1조7000억~2조9000억 개의 단어 조각으로 추정된다. 이를 통해 기존보다 장문의 문서를 생성할 수 있게 됐다. 기존 텍스트 응답은 4000단어로 제약이 있었으나 GPT-4는 2만5000단어까지 출력할 수 있다.GPT-4의 데이터세트는 오픈AI의 보이치에흐 자렘바 데이터세트팀 관리자의 주도 아래 35명으로 구성된 팀이 그동안 대대적으로 작업했다. 주된 작업은 ‘신규 데이터 추가’와 ‘유해 데이터 필터링’이었다. 우선 GPT-3 데이터세트에 마이크로소프트와 협업해 글로벌 대표 코드 저장소인 깃허브(GitHub)를 추가한 것이 가장 큰 작업이었다. 이로써 코딩 작성 능력을 획기적으로 끌어올렸다.그 외 변화로는 UC버클리수학, AMP 등 수식과 논리 등을 추가했다. 그 덕분에 복잡한 추론 작업이 필요한 시험에서 GPT-4는 인간의 평균 능력을 뛰어넘었다. SAT(미국수학능력시험) 1600점 만점에 1410점(상위 6%), 미국변호사시험 400점 만점에 298점(상위 10%), AP(고등학교 고급과정) 100%를 기록했다. GPT-4는 미국변호사시험과 대학원입학시험(GRE)에서 이전 버전을 능가했다. GPT-4는 개인이 세금을 계산하는 데도 도움이 될 수 있다며 오픈AI 그레그 브로크먼 회장이 시연했다.유해 데이터 필터링과 관련해 성 관련 텍스트 콘텐트를 양적으로 과감히 걸러냈다. 부적절한 성적 콘텐트를 포함할 가능성이 높은 문서를 식별해내고 내부적으로 훈련된 분류기와 어휘 기반 접근방식을 조합해 효과적으로 필터링했다.
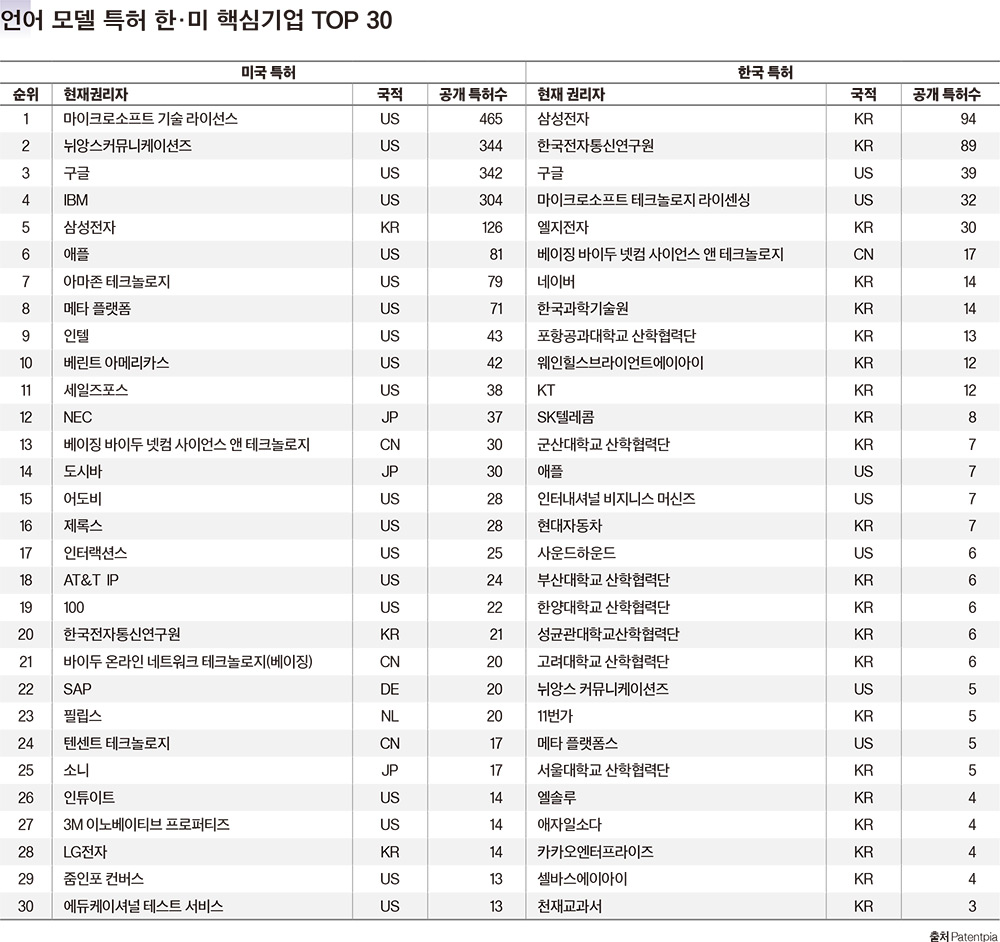
언어 모델 특허 핵심 기업: 미국은 MS, 한국은 삼성전자포브스코리아는 지난 호에서 챗GPT의 핵심기술인 적대적 생성 신경망(GAN, Generative Adversarial Network) 기술 특허 핵심 기업을 꼽은 데 이어, 이번 호에는 또 다른 핵심기술인 대규모 언어 모델(LLM) 기술 특허를 보유한 핵심 기업을 살펴봤다.LLM은 상대적으로 가장 최신 기술인 까닭에 지식재산권(IP) DB 페이턴피아에 등록된 특허는 미국 10건, 한국 2건에 불과했다. 이 중 대부분(미국 7건, 한국 2건)은 구글이 권리자였다. 이 중 파급력이 가장 큰 특허는 지난 2007년에 출원한 ‘분산형 모델의 인코딩 및 적응형, 확장가능한 액세스(Encoding and adaptive, scalable accessing of distributed models, 등록번호 8296123)로, 피인용 수가 35건으로 가장 많았다. 그 외 ‘기계번역에서의 대형언어모델’(8332207)등이 있었다. 그 외에 미국 해양전문기업 타예르마한(Thayermahan), 컴퓨터 처리 및 데이터 기업 레이시온BBN테크놀로지(Raytheon Bbn Technologies), 카네기멜론대가 각각 1건씩 보유했다.LLM 특허 관련 주요 키워드는 발생빈도(3), 대상 모델(2), 컴퓨터 저장 매체(2), 조잡한 모델(1), 상세 모델(1), 중간 번역(1), 예상 확장(1), 캐시 언어 모델(1), 후보 선택(1) 등이었다.한편, 키워드를 대규모 언어 모델이 아닌 언어 모델로 했을 경우 검색된 특허는 1만6495건으로, 미국 3738건, 중국 3391건, 일본 754건, 한국 589건, 유럽 428건이었다.미국 특허의 핵심 기업으로는 마이크로소프트 기술라이선스(465건), 뉘앙스커뮤니케이션즈(344건), 구글(342건), IBM(304건), 삼성전자(126건), 애플(81건), 아마존 테크놀로지(79건), 메타 플랫폼(71건), 인텔(43건), 베린트 아메리카스(42건) 등이었다.국내 특허의 핵심 기업으로는 삼성전자(94건), 한국전자통신연구원(89건), 구글(39건), 마이크로소프트 테크놀로지 라이센싱(32건), 엘지전자(30건), 베이징바이두 넷컴 사이언스 앤 테크놀로지(17건), 네이버(14건), 한국과학기술원(14건), 포항공과대학교 산학협력단(13건), 웨인힐스브라이언트에이아이(12건) 등이었다.삼성전자는 ‘언어 모델 학습 방법 및 장치, 음성 인식 방법 및 장치’(1022929210000), ‘언어 모델 학습 방법 및 이를 사용하는 장치’(1024498420000), ‘언어 모델을 압축하기 위한 전자 장치, 추천 워드를 제공하기 위한 전자 장치 및 그 동작 방법들’(1024883380000), ‘발화 인식 모델을 선택하는 시스템 및 전자 장치’(1024267170000) 등을 보유했다.
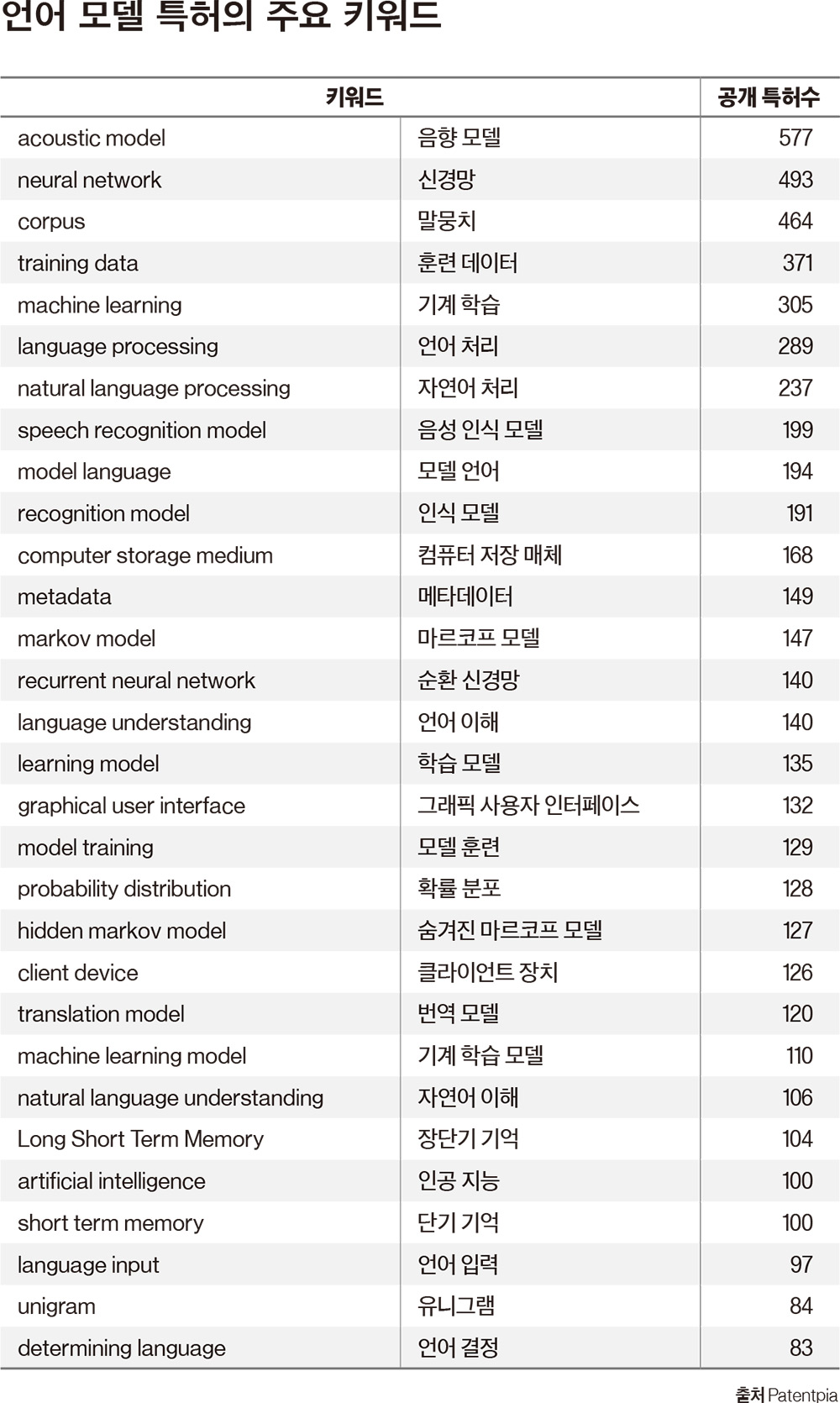
언어 모델 관련 특허의 키워드는 음향 모델(577건), 신경망(493건), 말뭉치(464건), 훈련 데이터(371건), 기계학습(305건), 언어 처리(289건), 자연어 처리 (237건), 음성 인식 모델(199건), 모델 언어(194건), 인식 모델(191건) 등으로 집약됐다.챗GPT를 개발한 오픈AI의 경우 2022년 미국 특허 1건, 출원 중 특허 1건이 있었다. 하지만 대규모 언어 모델이란 키워드를 포함하지 않았으며, 특허는 “구조화되지 않은 자연어의 다수의 노드를 갖는 복수의 그룹 대화를 수신하는 것을 포함하는, 질문에 대한 답을 결정하는 방법’(출원번호11,521,611), 출원 중인 특허는 ‘수신되는 자연어 통신에 대해 제안된 응답을 자동으로 생성하는 장치, 분류기와 자연어 생성 모델을 포함하는 장치’다. 두 건의 공통점은 자연어 의사소통을 구문 분석하거나 언어 모델을 사용해 응답을 생성하는 것과 관련해 인공지능 프로세스를 보호하기 위해 작성됐다는 것이다. 이것이 오픈AI의 기술을 구동하는 엔진으로 볼 수 있다. 그리고 기술을 구동하는 연료인 핵심 데이터세트와 더불어 모듈식 네트워크 구조 및 개별 모듈을 포함한 신경망, 학습, 역전파 등 경쟁 우위를 제공할 수 있는 핵심 알고리듬은 영업비밀로 부쳐져 있다.IP전문가 데니스 케세리스 베레스킨앤파르 로펌 파트너 등 다수는 “오픈AI의 2024년 예상 매출은 10억 달러(1조 3000억원)로 전망되는 가운데 과연 어떻게 비즈니스 모델을 가져갈 것인가에 질문이 제기된다”며 “이 질문의 답을 찾기 위해 IP를 개발, 획득, 활용하는 방법을 살펴봐야 한다”고 말한다. 그리고 “공개정보를 검토한 결과 오픈AI는 특허 및 영업비밀로 기술의 일부를 보호하고 나머지는 오픈소스로 만든다”며 “IP를 이용해 수익을 창출하고 오픈 소스 콘텐트를 이용해 이용자 사이에서 긍정적인 평판을 얻는, 이른바 개방형 IP자산과 배타적 IP자산을 모두 사용하는 혼합 전략은 AI회사에서 매우 유용하다”고 평가했다.하지만 오픈AI는 발명/저작권 침해와 같은 리스크를 안고 있으며, AI가 저작권을 부여받거나 발명가로 지정될 수 있는지가 불분명하기 때문에 결과물에 대한 특허 또는 저작권 보호를 청구할 수 있는지 등이 사용자에게 문제가 될 수 있다는 점을 지적했다.- 이진원 기자 lee.zinone@joongang.co.kr